Once you have identified candidate models, OpenVulnerability allows you to score them based on
user-defined criteria. Each criterion is defined as follows:
Screening Phase: selecting the candidate physical impact models
This step of the procedure involves identifying a list of candidate physical impact models among a given set of seed options. The ideal resource for performing this task would be an extensive database of single-hazard and interacting multi-hazard physical impact models that account for multiple asset typologies consistent with the GED4ALL taxonomy. This type of database should include a search engine actioned by the GED4ALL taxonomy string and should be constantly and systematically updated with relevant advancements in the literature. Although this type of resource is not yet available, related research efforts are ongoing, particularly around storing relevant attributes (e.g., analytical vs numerical vs empirical) of physical impact models (e.g., [127] for earthquake fragility and vulnerability, [128] for flood vulnerability), or producing harmonised data schemas that improve data interoperability within the different modules of a risk model (e.g., [129]).
This screening phase of the procedure involves:
- Defining three fundamental parameters: asset location, asset taxonomy string, and considered hazards. To maximise the model search results, these parameters should be defined with different levels of refinement. For example, “location” may be defined as “Kathmandu”, “Nepal”, or “Asia”; “taxonomy string” may be defined using only level-one GED4ALL attributes, or level-one and -two attributes combined, or also level-three attributes; “hazards” may be considered singularly, in relevant pairs or in relevant triplets, etc.;
- Performing an automatic search in OpenVulnerability. This should be performed multiple times for any combination of refinement in the above three parameters, starting from their most-refined definitions. Each match encountered during these searches constitutes a candidate model;
- Screen the candidate models to determine a subset to be ranked for quality in the subsequent phase. When screening, users should consider the possibility of developing ad-hoc adjustments to improve any given model. An example is to provide a modification coefficient to allow a physical impact model to consider an extra exposure parameter as an input (e.g., a height-dependent modifier to a model not accounting for building height, Section 4.4). The screening process is carried out according to three criteria: appropriateness of the damage scale (for fragility models) or the impact metric (for vulnerability and damage-to-impact models) concerning the considered application; the amount of extrapolation required to adopt a given model for the considered application; and the available documentation for a given model. The last criterion directly relates to the model scoring phase in the next step of the proposed procedure, which should avoid excessive guessing. Table 3 provides a set of example qualitative acceptance (i.e., screening) thresholds for the three criteria above, which can be modified appropriately according to user judgement for a considered application.
Model screening criteria: minimum thresholds for acceptance [N_ds, R_im, N_hp are defined by the user; example values: N_ds=1, R_im=20, N_hp=80]
| Screening criterion |
Screening criterion Suggested acceptance threshold |
| Damage/impact appropriateness |
Required DSs are defined (or N_ds DSs are missing). Required impact metric is modelled. |
| Required extrapolation |
Required IM range is covered (or R_im% extrapolation needed) |
| Documentation |
Documentation justifies N_hp% of the model’s assumptions (e.g., damage scale, IM selection, fitting methods) |
Scoring phase: selection of the most suitable model
For a given asset class, selecting the most suitable candidate model is ultimately a subjective decision of the user. Nonetheless, the selection process can be supported by a rational-yet-qualitative model scoring system based on key attributes related to the suitability of a given model.
This step of the proposed procedure enhances and combines different existing model scoring methods for single-hazard conditions and/or a single model typology. These methods provide criteria to evaluate the quality of asset-level physical impact models and are mainly focused on earthquakes. Porter [148] proposes a scoring system for analytical or empirical earthquake fragility models based on five criteria (data quality, relevance, rationality, documentation, and overall quality) and four scoring levels (superior, average, marginal, or not applicable). Meslem et al. [149] refined the previous scoring system for analytical earthquake fragility models. Rossetto et al. [150] further generalised the approach by Meslem et al. for analytical and empirical earthquake fragility and vulnerability models. The resulting scoring system is based on ten criteria grouped into four categories: data quality, representativeness of a specific class, rationality (e.g., obeying first principles), and documentation quality. Finally, Alam et al. [133] provide a two-step scoring system for earthquake and tornado fragility models of lifeline infrastructure. Based on a set of 16 criteria (related to regional applicability, IM, structural class, damage characterisation, data quality, analysis model and method, fragility derivation), the system involves 1) elicitating a group of experts to score each criterion in terms of importance; and 2) aggregating the expert’s responses to assign scores to each criterion.
Leveraging the above literature, this study proposes a scoring system for multi-hazard physical impact models related to different asset types and analysis methods. The adopted criteria are based on those in Rossetto et al. [150] but incorporate the following enhancements: (1) generalisation for a multi-hazard scope; (2) removal of criteria already considered in the screening phase (e.g., documentation); (3) addition of some bespoke criteria (details to follow); and (4) grouping of criteria to facilitate the final scoring part of the proposed procedure. Given a set of candidate physical impact models, the scoring phase of the proposed procedure involves:
- Scoring each candidate model against four suggested criteria: relevance, statistical refinement, model quality (defined differently for empirical or synthetic models), and user-defined requirements. Each criterion involves one or more attributes, which should be qualitatively scored "high", “medium”, or “low” according to the scheme described in Table 4. The “relevance” criterion involves the “geographical area” attribute, which captures the representativeness of a given model for a given area, “asset characteristics”, which considers how the parameters of the asset’s structural details, materials, and geometry within the model reflect those required for the considered asset class, and “IM”, which is related to the sufficiency and efficiency of the adopted IM(s). The “statistical refinement” criterion involves the “uncertainties” attribute, related to the refinement of the treatment of uncertainty for a given model, and “first principles”, which accounts for any functional inconsistency in the model (e.g., crossing of fragility functions for different DSs; unreasonably large/small maximum value of the impact metric of a vulnerability function). For empirical models, the “model quality” criterion includes the attributes “impact observations” and “IM observations” that are related to the level of error/bias involved in the fitted data, “constrained asset class” that captures how well the fitted data is suited to a single asset class, and “data quantity”, which involves the number of IM vs damage/impact observations used to fit the model. For synthetic models, this criterion involves “fidelity to mechanics”, which captures how well an analytical/numerical model reflects the mechanics of an asset subjected to one or multiple hazards, and “aggregation level”, which reflects the level of sophistication involved in the model (e.g., asset- vs component-level models). The attribute (and criterion) “user-defined requirements” reflects the level of compliance of the selected model with a set of user-defined features (e.g., time/state dependency, consistency of model assumptions across different asset classes). Note that although the model typology (e.g., synthetic vs empirical) can generally be considered a user-specific requirement, it can also be indirectly related to other requirements (e.g., no time-dependent empirical models are available, and therefore a synthetic model must be selected). Any attribute related to IMs should be disregarded when scoring damage-to-impact models. This set of criteria and attributes are suggested based on the available literature information and engineering judgement of the authors. Consistent with the spirit of this selection procedure, users are encouraged to add or remove specific criteria/attributes according to their specific needs;
- Each criterion has a prescribed weight. The analytic hierarchy process (AHP; [151]) is used to produce a mathematically consistent definition of the weights, which has already been successfully applied to engineering decision-making problems (e.g., [152]). According to this procedure, the user expresses an opinion on every possible pairwise comparison among the criteria. Each opinion quantifies how much criterion j is more/less important than criterion k. The results of the comparisons constitute a decision matrix. The desired weights are proportional to the first eigenvalue of this matrix. Further details can be found in [151]. The suggested weights for the criteria are 25% for “relevance”, 15% for “statistical refinement”, 40% for “model quality”, and 20% for “user requirements”. However, users are encouraged to apply AHP for their specific circumstances to derive case-specific weights;
- Given the adopted weights, scoring of the available models is carried out according to the technique for order preference by similarity to an ideal solution, or TOPSIS [153]. This procedure has been deemed suitable for engineering decision-making problems (e.g., [154]). First, the user scores each candidate model against the four criteria (using the qualitative scores “low, medium, or high”). The score assigned to a given criterion is the minimum score obtained for all of its attributes (e.g., the minimum score among the attributes “fidelity to mechanics”, and “aggregation level” quantify the score of the “model quality” criterion for synthetic models. For example, this approach penalises a refined component-by-component numerical model that neglects relevant damage mechanisms and/or impact sources). To be used as an input of TOPSIS, these qualitative scores should be expressed as numerical values. Alternatively, triangular fuzzy numbers may be used in a qualitative TOPSIS approach [155]. It is herein suggested to use 1, 2, and 3, respectively, for low, medium, and high. However, users are encouraged to test the sensitivity of the final result to these values and alter them if required. The weighted scores for a given criterion are used to define the ideal best and worst models, and the most suitable model maximises a trade-off between the distances from the ideal worst and best models [151].
Model scoring system: definition of scores for each attribute. [ATT, 〖OBS〗_1, 〖OBS〗_2, 〖OBS〗_3, 〖bins〗_1, 〖bins〗_2, 〖obs〗_1 are defined by the user; example values: ATT=4, 〖OBS〗_1=20, 〖OBS〗_2=200, 〖OBS〗_3=20, 〖bins〗_1=5, 〖bins〗_2=10, 〖obs〗_1=20]

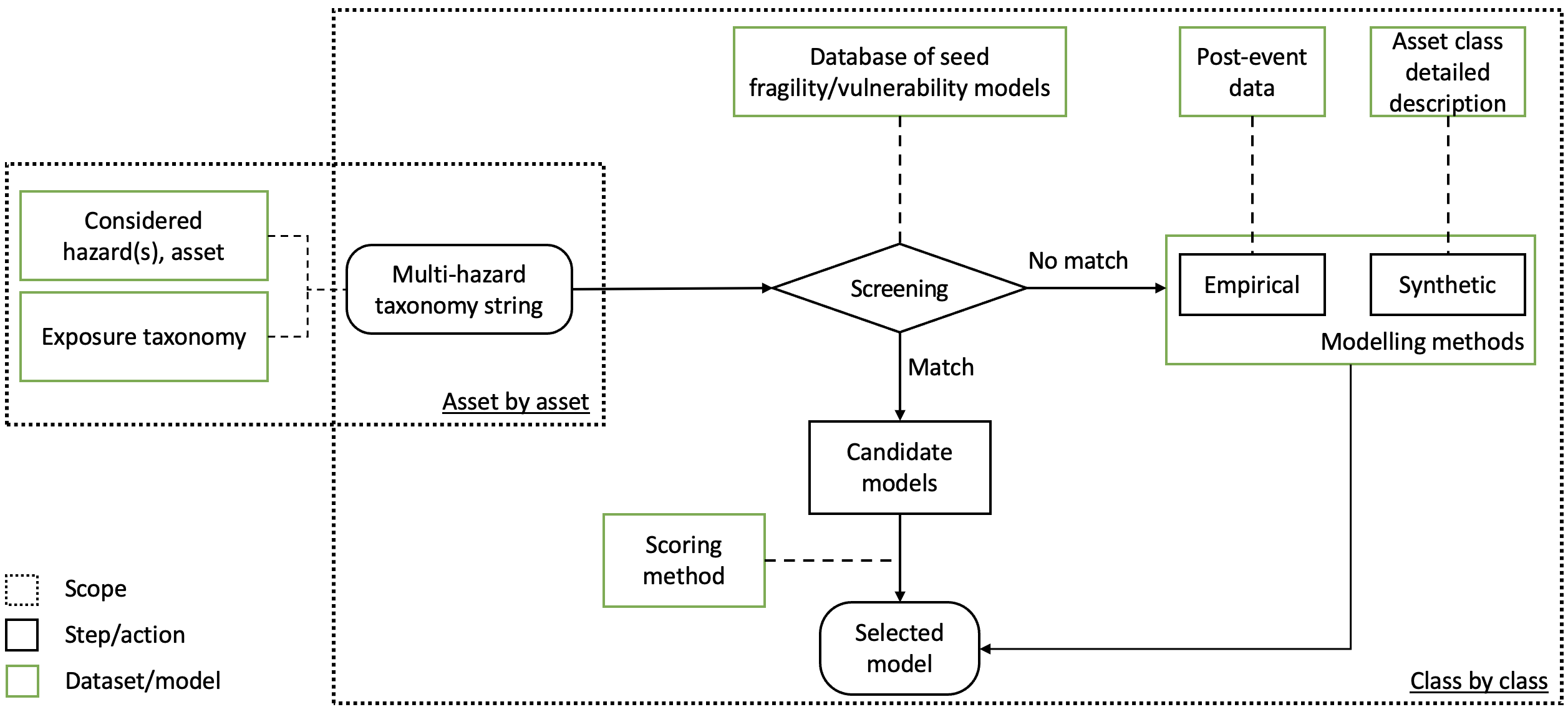 The proposed methodology for scoring, selecting, and developing physical impact models starts after selecting one or more natural hazards, independent or interacting, which are relevant for a selected case-study area. Although this is not strictly part of the proposed methodology, a useful tool to assist this choice is Thinkhazard (https://thinkhazard.org, last accessed June 2022), which provides a general view of hazard susceptibility on a global scale.
Next, assets within the considered area are grouped into classes according to a taxonomy model, which may require different sets of general parameters specific to the identified asset class and hazards (e.g., occupancy, geometry parameters, design level). The required asset class characteristics are codified in a multi-hazard taxonomy string and the minimum set of these parameters required for different hazard/asset-class combinations. The taxonomy string is then used to map the hazard/asset-class combination to relevant candidate impact models.
The selection should incorporate general considerations of the trade-off between simplicity, accuracy, and data requirements of the overarching risk model. The considered candidate models are then ranked according to a set of criteria to determine the most appropriate one.
The proposed procedure should be applied for multiple asset classes in parallel to determine whether physical impact models for different classes can be derived using a consistent methodology, which would lead to a desirable consistency in the damage/impact estimations of the considered risk assessment.
The main goal of this procedure is to facilitate the consistent appraisal and selection of a set of candidate physical impact models for use within risk modelling applications. The procedure may also be beneficial for application to new physical assets to be constructed as part of a risk-informed urban development process. Any values provided for relevant input parameters (e.g., specific criteria, threshold values for screening, scoring schemes, and weights; see below for more details) are only provided as recommendations; users are encouraged to adjust these parameters according to their specific needs.
The proposed methodology for scoring, selecting, and developing physical impact models starts after selecting one or more natural hazards, independent or interacting, which are relevant for a selected case-study area. Although this is not strictly part of the proposed methodology, a useful tool to assist this choice is Thinkhazard (https://thinkhazard.org, last accessed June 2022), which provides a general view of hazard susceptibility on a global scale.
Next, assets within the considered area are grouped into classes according to a taxonomy model, which may require different sets of general parameters specific to the identified asset class and hazards (e.g., occupancy, geometry parameters, design level). The required asset class characteristics are codified in a multi-hazard taxonomy string and the minimum set of these parameters required for different hazard/asset-class combinations. The taxonomy string is then used to map the hazard/asset-class combination to relevant candidate impact models.
The selection should incorporate general considerations of the trade-off between simplicity, accuracy, and data requirements of the overarching risk model. The considered candidate models are then ranked according to a set of criteria to determine the most appropriate one.
The proposed procedure should be applied for multiple asset classes in parallel to determine whether physical impact models for different classes can be derived using a consistent methodology, which would lead to a desirable consistency in the damage/impact estimations of the considered risk assessment.
The main goal of this procedure is to facilitate the consistent appraisal and selection of a set of candidate physical impact models for use within risk modelling applications. The procedure may also be beneficial for application to new physical assets to be constructed as part of a risk-informed urban development process. Any values provided for relevant input parameters (e.g., specific criteria, threshold values for screening, scoring schemes, and weights; see below for more details) are only provided as recommendations; users are encouraged to adjust these parameters according to their specific needs.